
论文阅读笔记-Cascaded Deep Video Deblurring Using Temporal Sharpness Prior
预备知识
well-posed/ill-posed
well-posed:适定性问题
1) a solution exits 解存在
2) the solution is unique 解唯一
3) the solution’s behavior changes continuously with the initial conditions 解稳定(初试条件不同,不会发生跳变)
ill-posed: 不适定问题,
1) 通常不满足以上条件的二三条,比如图像超分,去雨去雾去模糊等任务,解有无数种,且都是不稳定的。
2) 英文解释:In most cases,thera are several possible output images corresponding to a given input image and the problem can be seen as a task of selecting the most proper one from all the possible outputs.
affine transformation
affine transformation:图像仿射变换
是一种二维坐标(x,y)到二维坐标(u,v)的线性变换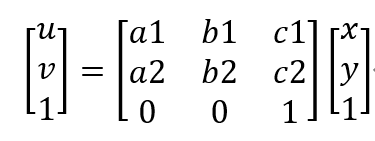
膨胀卷积、反卷积
膨胀卷积:Dilated Convolution
增加感受野
kernel膨胀为k+(k-1)×(d-1),即每个相邻加入了(d-1)个空格
之后为正常的卷积操作output=n+2p-[k+(k-1)×(d-1)]/s+1
若希望input_size = output_size,带入公式计算即可出padding即可
反卷积:ConTranspose2d
通常用于上采样
变化前:
feature map:height×height
kernel:stride,size,padding
变换后:
feature map插值为:height’ = height+(stride-1)×(height-1),即每个相邻处插(stride-1)个0
kernel:stride=1固定不变,size不变,padding’=(size-1)/2
带入卷积公式可化简为:H_out=(Height-1)×stride-2×padding+size (+output_padding)(height,stride,padding,size均为变化前的值)
kernel_size=4, stride=2, padding=1的参数设置可以保证一倍上采样
反卷积会引入棋盘效应(checkerboad artifacts)
optical flow
optical flow:光流
概念:空间中运动的物体在观察成像平面上像素值的瞬时速度,在很小的时间间隔里(例如视频前后两帧之间),也等同于目标点的位移。光流是由于场景中前景目标本身的运动、相机的运动或者两者共同运动所产生的的。
光流矢量:通常降二维平面上坐标点的灰度瞬时变化率定义为光流矢量。
光流可视化:光流场图片中每个像素的位移矢量都可以分解成x方向和y方向的矢量,所以光流估计后得到的图像是一个和原图像大小相等的双通道图像(分别代表x方向和y方向的运动方向和速度),颜色代表运动方向,深浅(亮度)代表运动速度。
光流和图像的映射关系:(用hsv图像表示)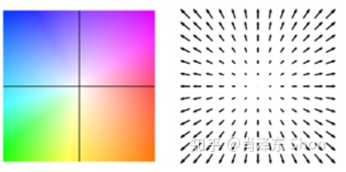
稠密光流和稀疏光流:稠密光流需要将图像中所有像素的光流都计算出来。稀疏光流只针对图像中的若干个特征点,例如一些特征明显(梯度较大)的点进行光流估计和追踪。
optical flow estimation
optical flow estimation:光流估计法模型
Lucas-Kanada:稀疏光流估计法
两个重要假设:
(1) 亮度不变假设
假设待估计光流的两帧图像的同一物体的亮度不变。这个假设通常是成立的,因为环境光照通常不会发生太大的变化。
假设在t时刻,位于(x,y)像素位置的物体,在t+Δt位于(x+u,y+v)位置,基于亮度不变假设,有:
(2) 领域光流相似假设
假设领域内的所有像素点光流值一致。通常一个小的图像区域里像素移动的方向和大小基本是一致的,因此假设是合理的。
领域内的所有像素都有下式:
所以LK算法求解的是一些亮度变化明显的角点(稀疏光流)的光流
(3) 时间间隔很小
上述假设都基于短时间内的两帧,即随着时间的变化不会引起位置的剧烈变化,只有在小运动的情况下才可以用前后帧之间的灰度变化去近似灰度对位置的偏导数。
PWC-Net
整体框架: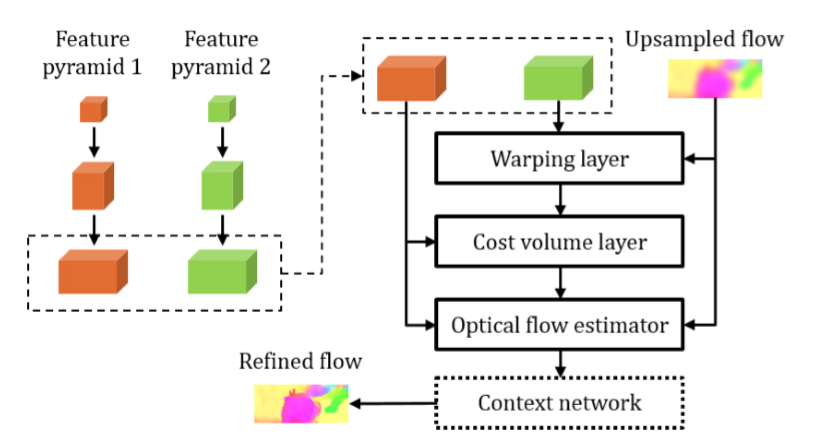
(1) Feature pyramid extractor
建立了7层金字塔(包含原图),每一层利用上一层预测的光流图对第二帧warp,与第一帧校对。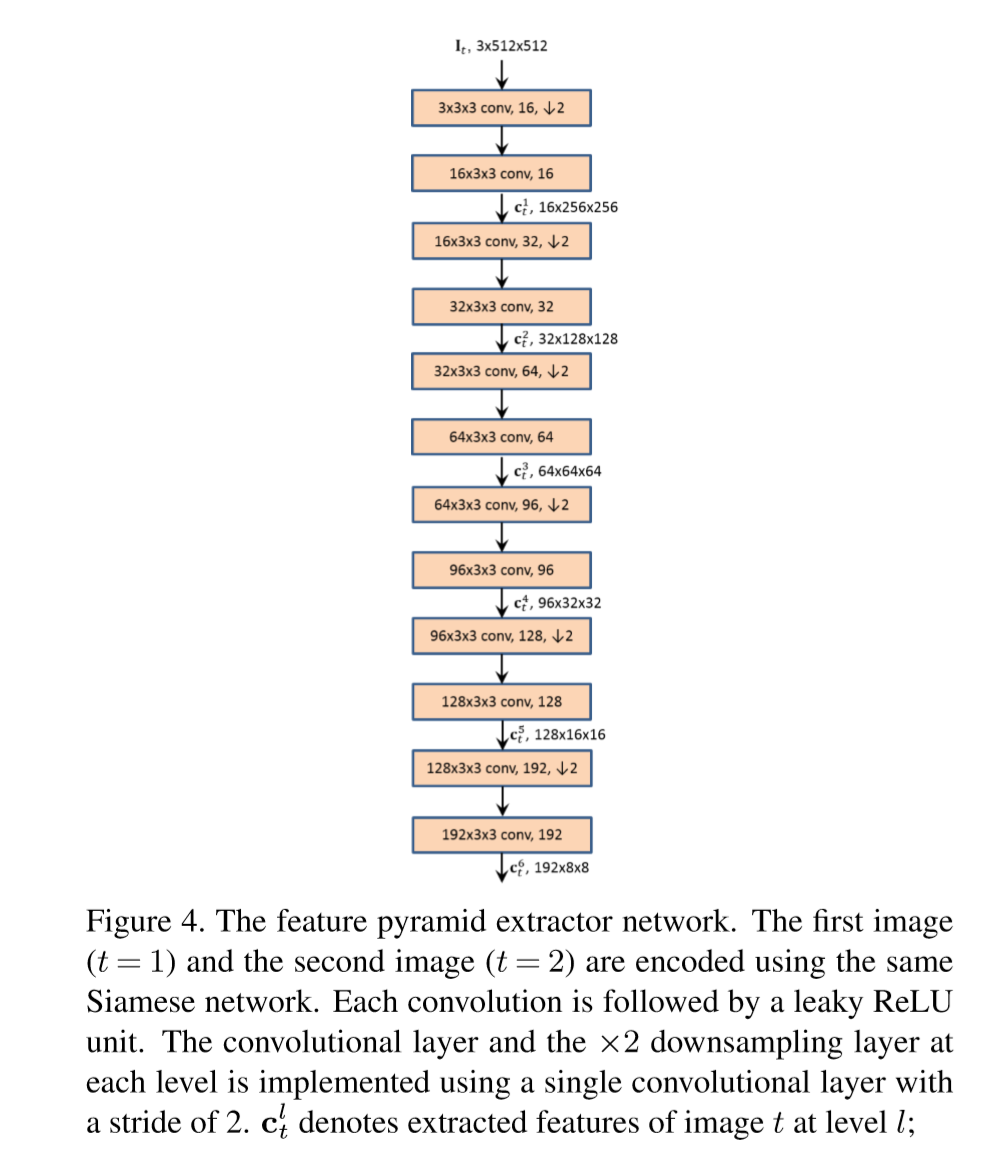
(2) wraping layer
利用nn.functional.grid_sample将第二帧图像和光流图,用双线性插值矫正成第一帧.
mask作用:有一些点的flow偏移过大,warp操作里忽略掉这些点。
(3) Costvolumelayer
第一帧的每一个像素点,与第二帧图像同样位置的像素点,周围d²的矩阵内的每个像素在该通道内做点乘求和,代表像素的匹配程度,cv后的尺寸为
H×W×d²
(4) Opticalflowestimator
Opticalflowestimator网络的输入由四部分组成:第一帧的feature map、cv、前一层上采样后的光流图、前一层上采样的feature map,此处采用DenseNet结构优化,每一层的输入都会叠加到后几层的输入上。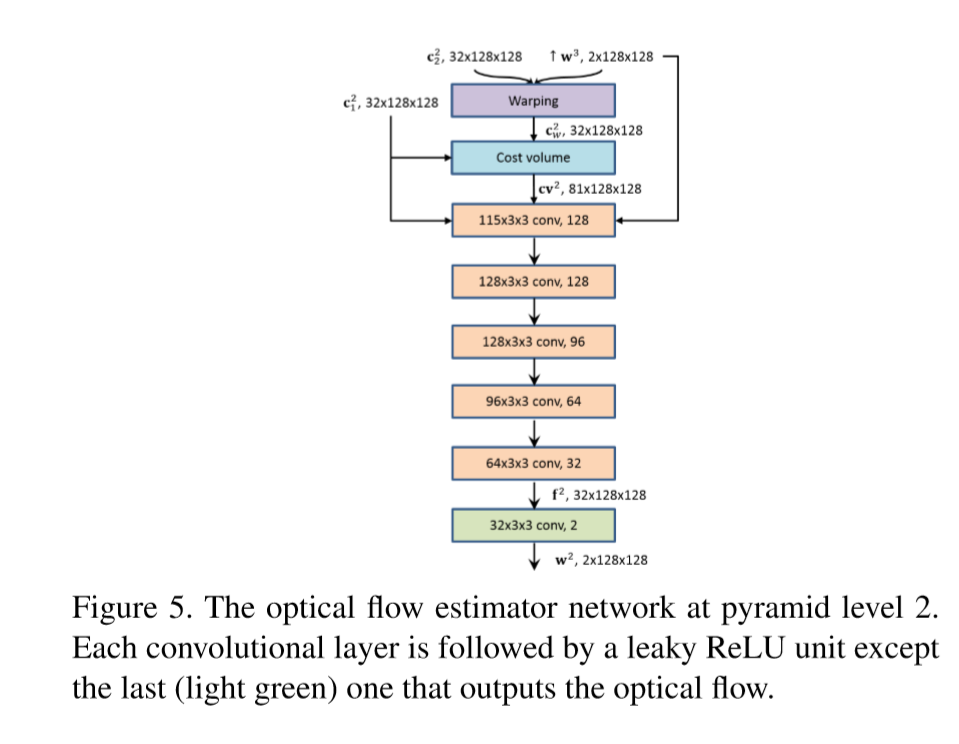
(5) Context network
输入由Opticalflowestimator网络部分的倒数第二层和预测光流图组成,做膨胀卷积,输出的结果加上原光流图做优化。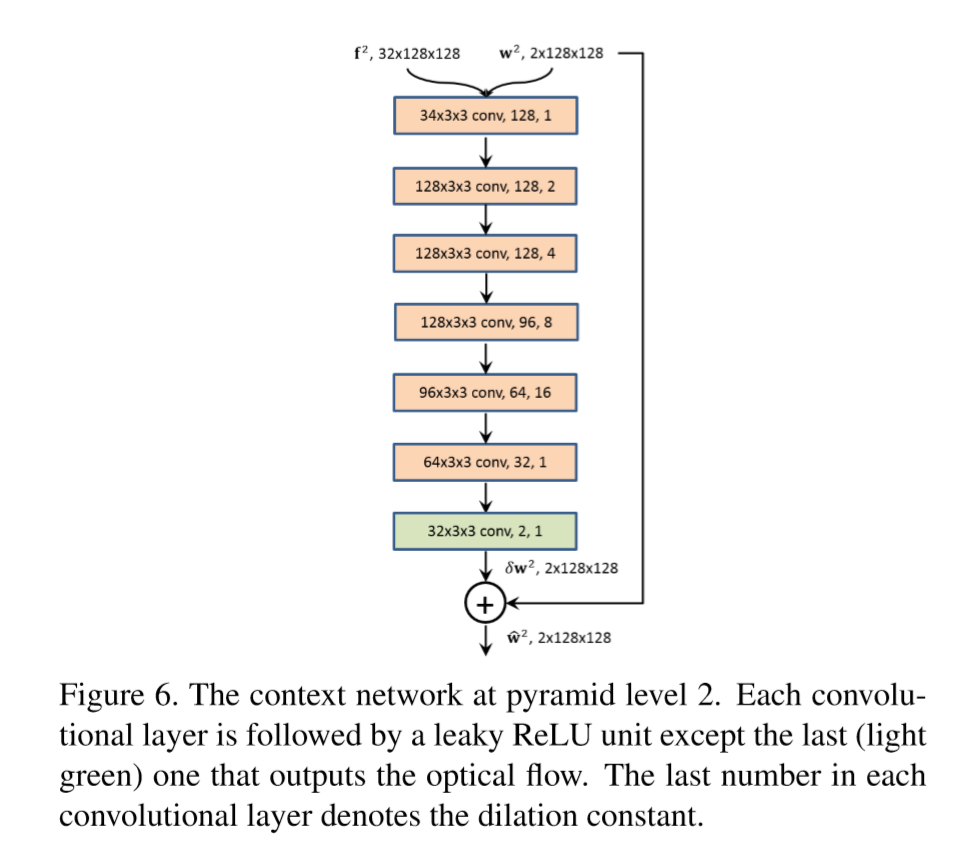
(6) 实现细节
- 7层金字塔光流图只计算到第二层,然后直接上采样双线性插值到原尺寸。
- gt的光流图下采样了20倍(并没有在每一层下采样20倍),所以代码的estimate_flow需要×20
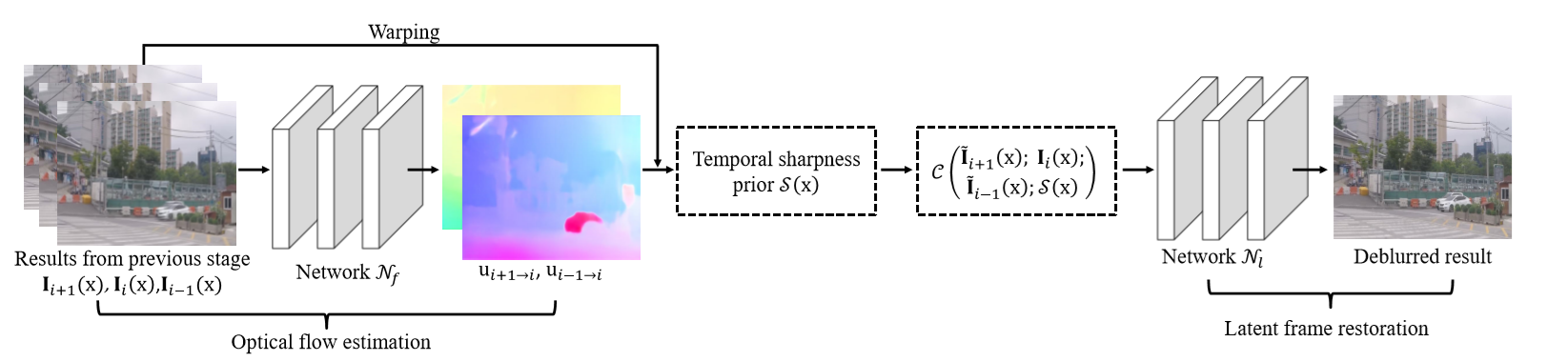
CDVD-TSP(Cascaded Deep Video Deblurring Using Temporal Sharpness Prior)
Cascaded(串联训练)
串联:利用五帧来预测清晰图片,确保optical flow是在较清晰的中间层latent frame上预测出来的,同时利用预测出来的光流图和restoration网络来生成deblur后的帧,随后在生成的清晰帧上再预测光流图,可以使得整个流程不停迭代下去。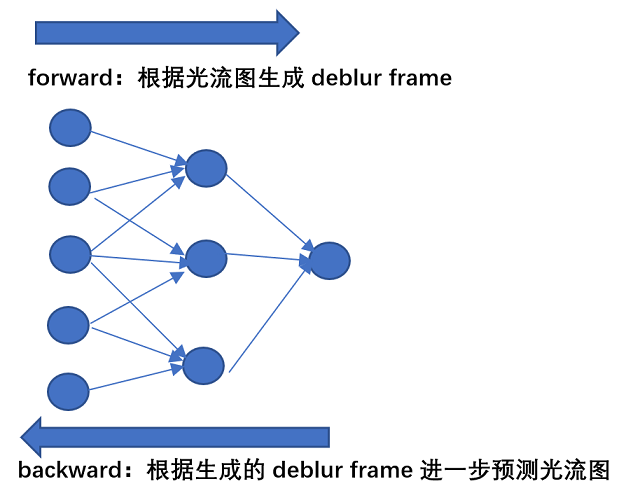
optical flow estimation
PWC-Net
temporal sharpness prior
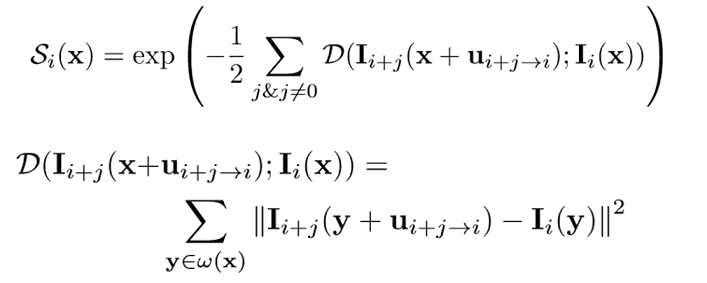
latent frame restoration
注:
input_channel:10(第i帧+第i-1帧warp后结果+第i+1帧warp后结果+tsp)
蓝色部分为三个残差块叠加在一起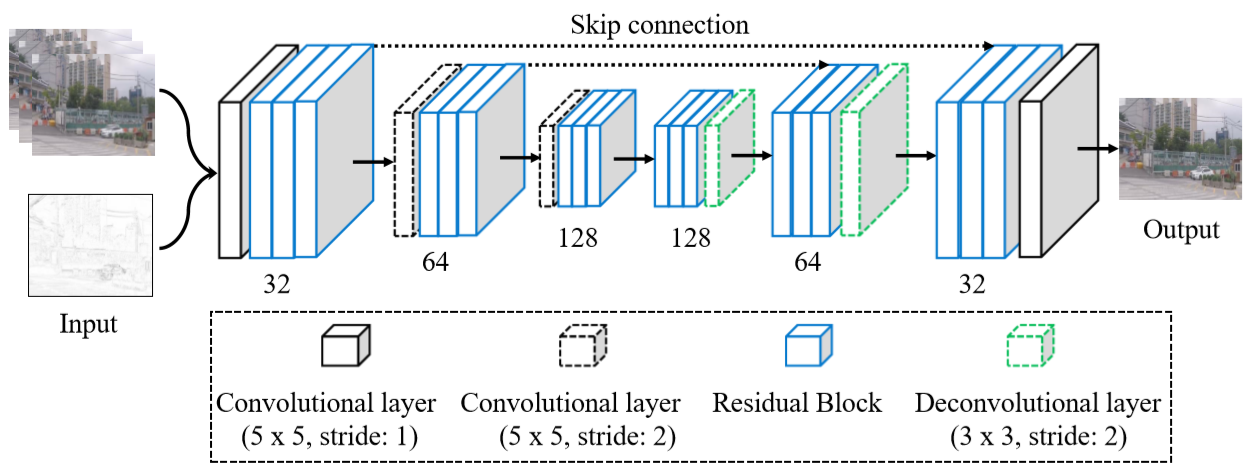
overview of the proposed method at one stage
总结
1. 避免由传统方法先验知识引起的复杂能量方程很难求解的问题。
2. 避免在blur image上预测的光流图不准。
3. 利用temporal sharpness prior的先验知识可以优化结果。
4. Ablation实验结果表明optical flow,cascaded training,temporal sharpness prior缺一不可,缺少任何一步都会使结果降低。