
论文阅读笔记-Swapping Autoencoder for Deep Image Manipulation
预备知识
conditional gan
转跳链接
条件GAN,生成网络还需要附加一定的条件
附加的条件可以是文字,也可以是图片
非饱和损失函数non-saturating adversarial loss
转跳链接
GAN discriminator loss:max log(D(x))+log(1-D(G(z))
GAN generator Saturating loss:min log(1-D(G(z)))
GAN generator Non-Saturating loss:max log(D(G(z)))
非饱和损失函数能在训练早期提供更大的梯度
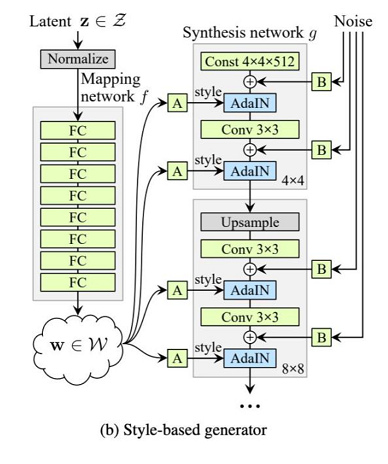
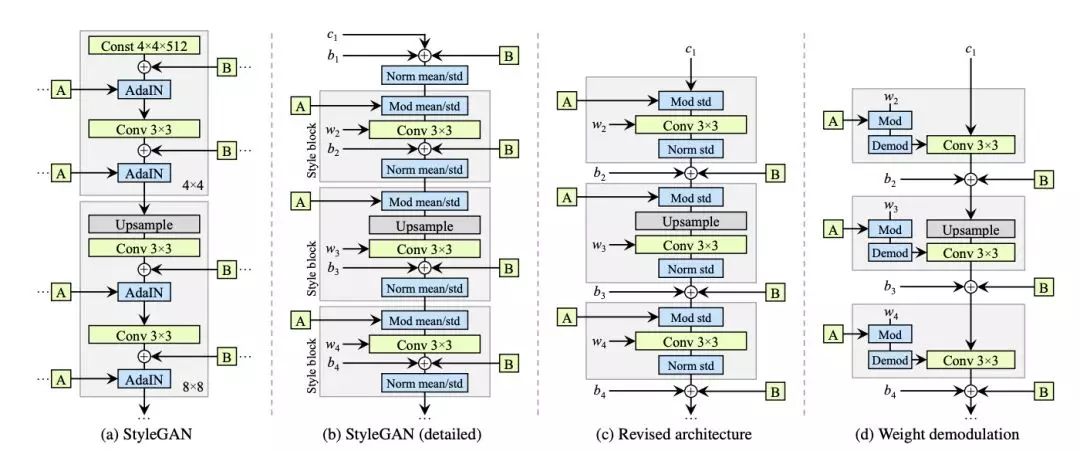
StyleGan & StyleGan2
Swapping Autoencoder for Deep Image Manipulation
概述
本文提出了一些自动编码的交换策略,可以解决一系列的图像转换问题,包括纹理交换。
它通过把输入图像转换成latent code,分为structure code和texture code,通过交换这两部分实现合并成一张新的生成图片。
image editing的问题:
从外部数据集获取的信息和输入图像自己本身信息的矛盾。
若外部数据集依赖过多,生成的图像就不像输入图像了,这就很难满足editing这个操作。
若对输入图像依赖过多,外部的数据集就失去了价值。
为了解决这个问题,我们为autoencoder设计了两个latent code module,一个捕捉图像内部的可视化信息(texture),另一个捕捉其余的信息(structure)。不使用unconditional gan的原因:处理图片的效果不好。unconditional gan从一些易于采样的分布中(例如高斯分布)学习了一种映射。一些方法改进了预训练好的unconditional gan去寻找latent vector,来重塑输入图片。但我们展示出这些方法是不准确的并且比我们的模型慢。
不使用conditional gan的原因:需要先验。相比于其他使用条件gan的方法,本方法提出的框架即可以处理图像合成问题,也可以用于处理图像,这个框架在训练阶段时可以用过一个或者很小的样本得到。并且对比a single-image GAN,我们的模型在单一图片测试时即快又不需要很大的运算量。
相比与其他使用latent code的方法,本方法的code space是学习得到而不是从固定的分布中取样得到的,这就使得方法变得更灵活。
相比与将content和style分开的方法,本方法有三个优势:1.无监督,无需依赖于class label,pairwise image similarity,images pairs with same appearances,object locations等信息。2.从输入图像中提取的structure code和texture code代表着图像不同方面的信息,并且合并后可以生成更高品质的图片。3.无需ground truth domain labels。
相比于传统的style transfer方法,内容迁移使用perceptual distance,风格迁移使用texture statistics, e.g., a Gram matrix.只能转移低级的特征而无法转移更大尺度的语义特征,也有其他方法但只局限于局部的风格转变。我们的方法的可以转移语义上有用的信息,比如教堂的整体结构。
5.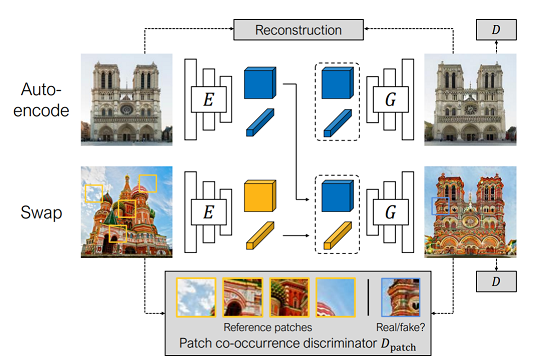
The structure code is a tensor with spatial dimensions; the texture code is a 2048-dimensional vector.
the texture code must capture the texture distribution, while the structure code must capture location-specific information of the input images
实现细节
网络细节

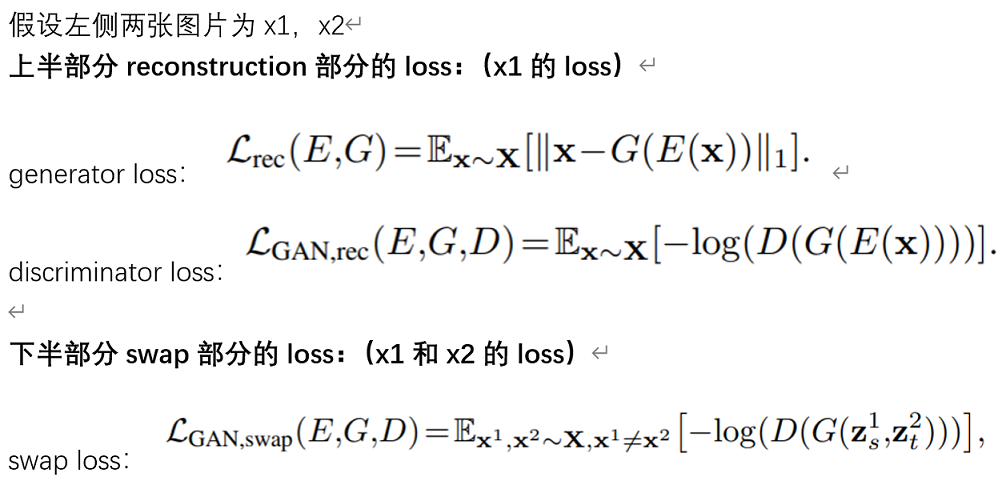
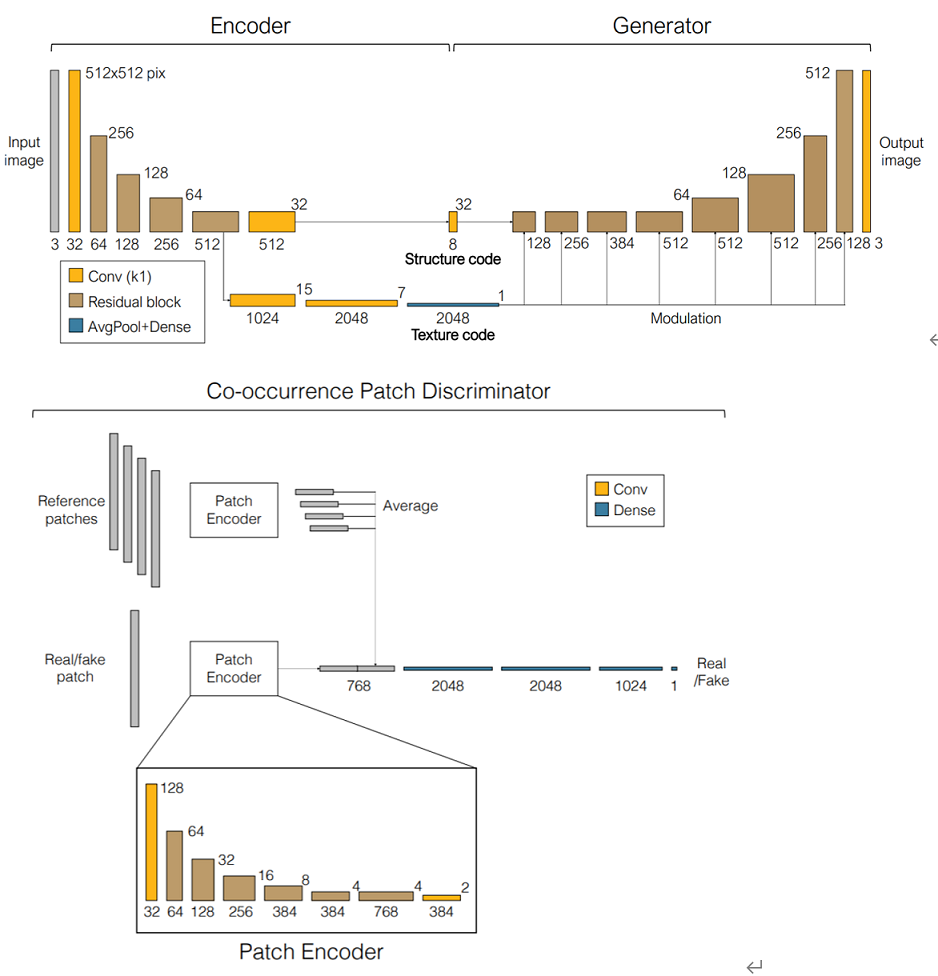
structure code:基于全卷积网络和感受野,提取的是空间的领域信息
texture code:在卷积层里用reflection padding或no padding,最后得到的是一维向量,排除了空间信息的干扰。
实验细节
image reconstruction
image swapping
image editing
image translation
具体看word