
论文阅读笔记-Scale-recurrent Network for Deep Image Deblurring
Scale-recurrent Structure
在现有的多尺度方法中,求解器及其每个尺度的参数通常是一样的。因为在每个尺度上,我们的目标都是求解同样的问题。每个尺度上使用不同的参数可能会引入不稳定性并带来非限制性解空间的额外问题。另一个问题是输入图像可能会有不同的分辨率和运动尺度。如果允许每个尺度上都进行参数调节,那么这个解可能会在特定图像分辨率或运动尺度上过拟合。
我们提出在不同尺度上共享网络权重,从而显著降低训练复杂度以及引入明显的稳定性优势。这种做法有两种好处。首先,这能显著减少可训练参数的数量。即使用同样数目的训练数据,在共享权重的循环利用下的效果也像是有多倍数据来学习参数,这实际上相当于在尺度上进行的数据增强。其次,我们提出的结构可以利用到循环模块,其状态传递能隐含地获取各个尺度上的有用信息并帮助图像恢复。
Encoder-decoder ResBlock Network
编码器-解码器 ResBlock 网络会放大各种 CNN 结构的优势并实现训练的可行性。同时,这还会产生非常大的感受野,这对运动模糊很大的图像的去模糊至关重要。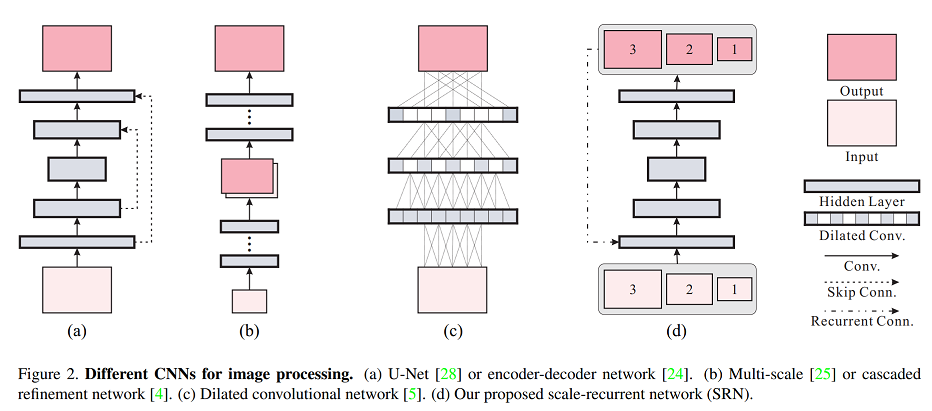
网络结构
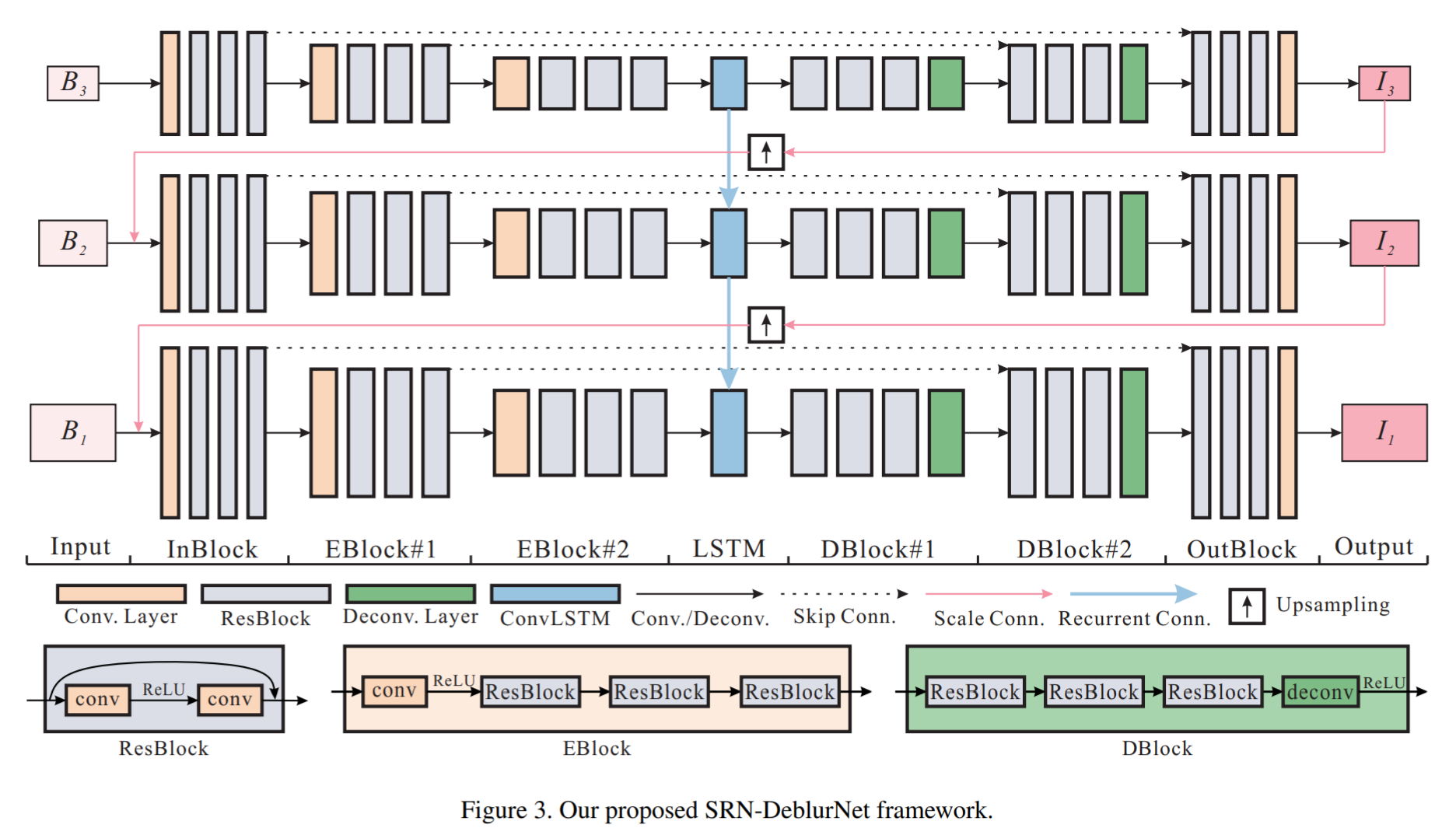
Scale-recurrent Network(SRN)
- 在每一个尺度上,以两张图像作为输入,一张模糊图像,一张上采样后的去模糊图像。同时还在中间输入了隐藏状态的特征。
- 循环网络用ConvLSTM.它能在利用时间相关性的同时利用空间相关性。
- 不同尺度之间对图像和feature的上采样都使用双线性插值(bilinear interpolation),因为简单有效。
用残差网络构造的编解码器
- 编解码器用对称的结构先把输入数据编成小尺寸、多通道的特征图,然后把特征图解码成与与输入相同shape的输出。跳跃连接(skip-connection)在编解码器中广泛用来连接不同level的特征,有利于梯度传播与加速收敛。一般,编码器包括几级步长不为1的卷积,解码器包括几级解卷积或resize。
- 然而直接使用简单的编解码器有以下缺点:层数少导致感受野小,若层数过多又会导致特征图尺寸过小而不能充分保留空间信息,且层数过多还会增加参数,使网络难以收敛。
- 本文将残差模块用于编解码器,所有残差块没有BN层。在每一个编码残差块(EBlocks)中,先通过步长为2的卷积,将尺寸缩小一半,同时将特征维度增加一倍。然后通过若干个残差网络,每个残差网络包含两层卷积。在每一个解码模块(DBlocks)中,结构与编码模块(EBlocks)对称,即若干个残差网络和一个解卷积层(deconvolution),将尺寸增加一倍,特征维度减少一半。
- 隐藏层隐藏状态包含了有用的信息和模糊样式,传递到下一层有利于产生更有的结果。
- 整个网络流程可以用下图表示
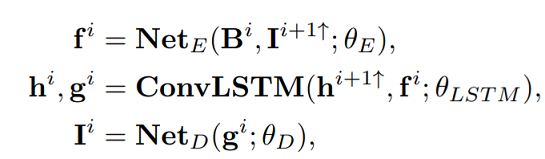
Bi表示该层的模糊图像,I^(i+1) ↑表示上一层得到的deblur图像再经过上采样的结果,h^(i+1) ↑表示上一层的LSTM传递的feature - 对每一个尺度,可以依次分成几部分:InBlocks 2×EBlocks ConvLSTMBlocks 2×Dblocks OutBlocks;
InBlocks产生32通道特征,两个EBlocks分别产生64,128通道,DBlocks和OutBlocks与前面对称。
每一层卷积后都用ReLU层,所有核的尺寸都为5.
损失函数
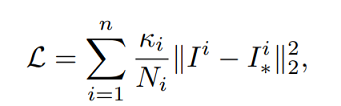
L2 loss:output与gt做平方差
ki=1
Ni是像素个数
每个scale做l2 loss,所有scale相加是整个网络的loss