
Pixel-Level Cycle Association: A New Perspective for Domain Adaptive
概述
语义分割近年来获得非常大的进步和发展。但是当分割网络执行跨域(cross-domain)预测任务时,性能还远不能令人满意。例如,分割网络在易于获得标注的 synthetic data 上训练,在真实场景图片上进行分类,性能会发生大幅下跌。
这种性能下降是由于目标域(target domain)和源域(source domain)图片的分布(风格,布局,等)不同所造成的。领域自适应语义分割(Domain Adaptive Semantic Segmentation)就是利用带标注的源域数据和无标注的目标域数据来减小或者消除域漂移(domain shift)带来的性能损失。
domain adaptive semantic segmentation:我们有标记的source data S和未标记的target data T,tatget的种类和source一样。 我们需要训练一个网络,把每一个target pixel分类成正确的类别,网络使用source和target一起训练。
动机
对于领域自适应语义分割,以前的方法通常基于 adversarial training,让图片或者 feature map 在不同 domain 之间变得不可区分。但是这些方法更多地关注全局或者整体的相似度,忽略了域内和域间的像素间关系,尽管能够在一定程度上消除域差异,其导致的 feature 并不具备非常好的辨别性,因而影响分类性能。这篇论文充分利用像素间的相似度来消除域差异,同时提高 feature 的辨别性。
方法
Pixel-Level Cycle Association(像素级别的循环关联)
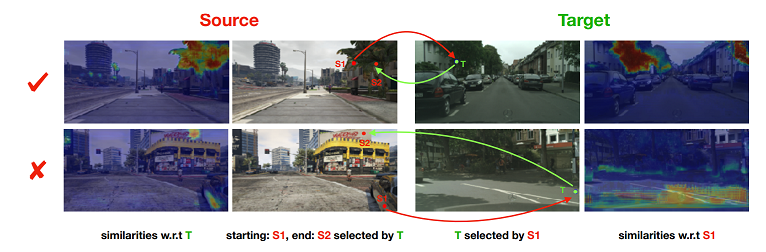
如上图所示,对于随机采样的 source 和 target 图片,我们首先建立他们像素级别的关联。我们利用像素级别的循环一致性(pixel-level cycle consistency)来建立这种关联。
具体来说,对于任一 source 图片中的像素 S1,我们在 target 图片中选择与之相似度最高的像素 T。然后,对于选择的 target 像素 T,我们反过来选择与之最接近的 source 图片中的像素 S2。如果 S1 和 S2 属于同一个类别,我们则建立 S1–> T –> S2 的关联,否则,关联不成立。
cosine similarity: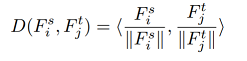
余弦相似度,用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。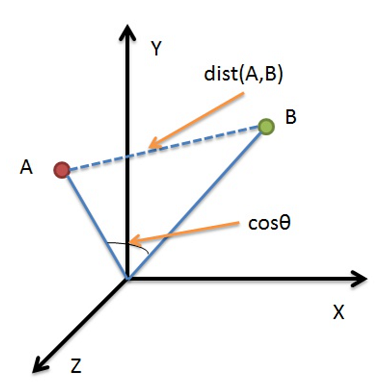

最直接的方法是在训练的时候,maximize它们的特征相似度,然而,像素级特征除了包含语义信息外,还包含丰富的上下文信息和结构信息,直接最大化它们的相似性可能会引入bias,因为像素对来自不同的图像,它们的上下文或结构可能不完全相同。因此采用对比增强的方法,即让相关联的像素对的相似度比其他像素对更高(与之相关的加强,不相关的降低),loss如下: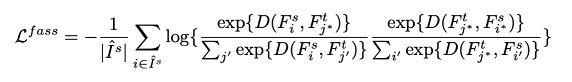
类似于softmax函数,可以理解为让i到j*,再从j*到i*的概率最大(乘法法则)。
对上式公式,需要做contrast 归一化(减均值/标准差),对比学习的核心思想是最大化相似性和最小化差异性的损失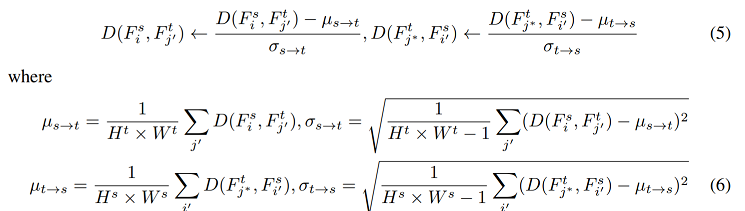
简而言之,就是让关联的 source 和 target 像素对的相似度相比于其他可能的像素对更高。
上述操作运用在softmax操作之前。
Gradient Diffusion via Spatial Aggregation(通过Spatial Aggregation的梯度扩散)
通过循环关联,我们可以建立 source 和 target 像素之间的联系。但是,通常只有部分 target 像素可以和 source 像素成功地建立起关联。原因有两个,一是循环关联倾向于选择最容易关联到的 target 像素;二是由于域差异,对于当前 source 图片的部分像素,target image 中在本质上可能就不存在应该与之关联的像素。
为了给更多样化的 target 像素提供 supervision,对每个 target 像素点,我们采取 spatial aggregation 生成新的 feature,然后基于 aggregated feature 建立循环关联,如下图所示。
通过这种方式,在 backward 的过程中,每个关联到的 target 像素点作为 seed 把传递给它的 gradients “分发给” 图片中的其他像素,其大小取决于其他像素点和 seed 像素点之间的相似度。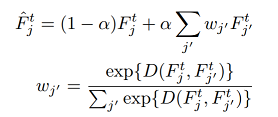
α是一个[0,1]的常量,代表聚集特征的比例。作者经验性的认为设置在[0.5,1]较好,本文设置为0.5。
这样做的目的是希望在训练的时候尽可能cover到所有的target像素点,至于每个像素点的权重,还是采用contrast的方法,与之最相关的分配大一点的权重,反之,小一点。论文中把\(F_j^t\)叫做seed点。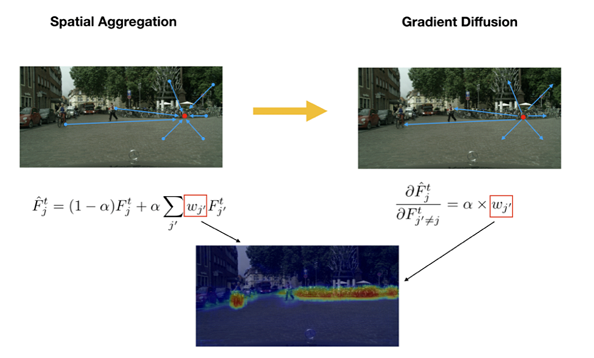
Multi-Level Association(多层次关联)
作者认为仅在特征图上使用像素循环关联,容易针对source图像产生过拟合,从而降低表现,这是由于特征图的域差异(domain discrepancy)没有被完美的消除。从而提出除了在 feature 层建立和增强循环关联以外,我们还在分割网络预测的像素的 probability distribution 上建立循环关联。方法跟在 feature 上的做法一样。唯一不同的是,我们采取负的 Kullback-Leibler (KL) divergence 作为相似度度量, 即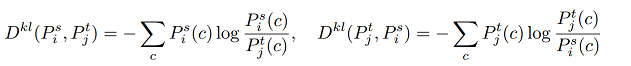
\(P_i^s (c)\)代表source piexl i属于类别c的概率,\(P_j^t (c)\)同理。
KL散度:表示的就是两个概率之间的差异,散度越小,说明之间越接近,那么估计的概率分布于真实的概率分布也就越接近。添加负号结果相反。
对应的 loss 为: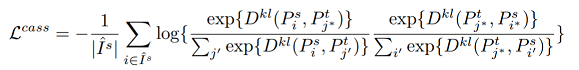
同理我们在softmax操作之前进行归一化,也使用梯度扩散。
在使用了multi-level cycle association之后,不仅可以减少source的过拟合,也有利于挖掘和利用多粒度像素关系(multi-granular pixel-wise relationships),他们之间互补,并且都有利于减轻domain shift。
整体loss
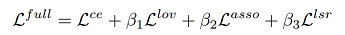
第一项:source data的pixel-wise cross-entropy loss,I^s表示source image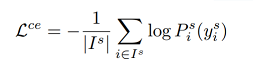
第二项:the lovász-softmax loss:用来缓解数据不平衡的负面影响,使得target predictions更加平衡。
第三项:multi-level association loss消除domain discrepancy(见前两节loss)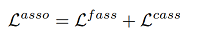
第四项:平滑标签项,M是所有的类别,公式含义是对所有输出的预测结果平滑操作,能够更加反映类与类之间的关系,在数据拟合和跨域关联之间进行trade-off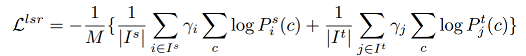
消融实验

source-only表示只使用source data训练数据
“Sim-PLCA”指的是直接增强关联像素对相似度的方式,“PLCA w/o. SAGG”指的是不采用 spatial aggregation 建立关联。